Is K nearest neighbor used for classification?
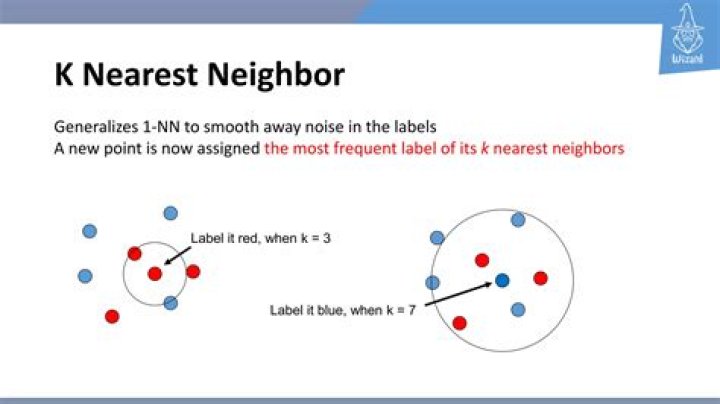
K Nearest Neighbor algorithm falls under the Supervised Learning category and is used for classification (most commonly) and regression. It is a versatile algorithm also used for imputing missing values and resampling datasets.
What is nearest Neighbour classification?
The simplest variant of nearest neighbor classification may be formalized as follows: For any metric object space O, let TS \subseteq O denote the set of labeled training data and {d:O. \times O \to \Re _0^+ } is the chosen and thus distance function that reflects the dissimilarity of any two objects from O.
What are the characteristics of K Nearest Neighbor algorithm?
Characteristics of kNN
- Between-sample geometric distance.
- Classification decision rule and confusion matrix.
- Feature transformation.
- Performance assessment with cross-validation.
What type is KNN?
Summary. The k-nearest neighbors (KNN) algorithm is a simple, supervised machine learning algorithm that can be used to solve both classification and regression problems. It’s easy to implement and understand, but has a major drawback of becoming significantly slows as the size of that data in use grows.
Where is KNN used?
Usage of KNN The KNN algorithm can compete with the most accurate models because it makes highly accurate predictions. Therefore, you can use the KNN algorithm for applications that require high accuracy but that do not require a human-readable model. The quality of the predictions depends on the distance measure.
What is K Nearest Neighbor machine learning?
K-Nearest Neighbour is one of the simplest Machine Learning algorithms based on Supervised Learning technique. K-NN algorithm assumes the similarity between the new case/data and available cases and put the new case into the category that is most similar to the available categories.
What is nearest neighbor classifier in data mining?
KNN (K — Nearest Neighbors) is one of many (supervised learning) algorithms used in data mining and machine learning, it’s a classifier algorithm where the learning is based “how similar” is a data (a vector) from other .
What is K-Nearest Neighbor machine learning?
What is the advantage of K-nearest neighbor method?
It stores the training dataset and learns from it only at the time of making real time predictions. This makes the KNN algorithm much faster than other algorithms that require training e.g. SVM, Linear Regression etc.
What is K search?
k-nearest neighbor search identifies the top k nearest neighbors to the query. This technique is commonly used in predictive analytics to estimate or classify a point based on the consensus of its neighbors.
What is k nearest neighbor algorithm?
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space.
What is the nearest neighbor algorithm?
Nearest neighbour algorithm. The nearest neighbour algorithm was one of the first algorithms used to determine a solution to the travelling salesman problem. In it, the salesman starts at a random city and repeatedly visits the nearest city until all have been visited.
What is the nearest neighbor analysis?
Nearest Neighbour Analysis An example of the search for order in settlement or other patterns in the landscape is the use of a technique known as nearest neighbour analysis. This attempts to measure the distributions according to whether they are clustered, random or regular.
What is k nearest neighbor?
K nearest neighbors is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions).