What is K-fold?
Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into.
How does K-fold work?
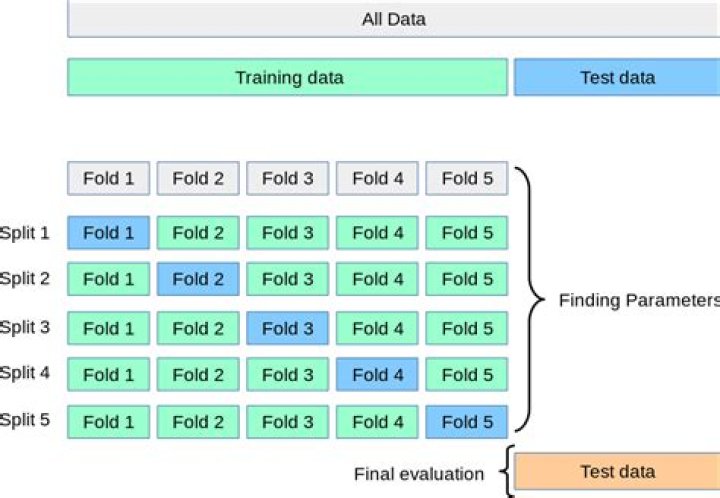
K-Fold CV is where a given data set is split into a K number of sections/folds where each fold is used as a testing set at some point. Lets take the scenario of 5-Fold cross validation(K=5). This process is repeated until each fold of the 5 folds have been used as the testing set.
What is K-fold accuracy?
k-fold cross-validation is one of the most popular strategies widely used by data scientists. One can build a perfect model on the training data with 100% accuracy or 0 error, but it may fail to generalize for unseen data. So, it is not a good model. It overfits the training data.
How do you read K-fold?
k-Fold Cross Validation: When a specific value for k is chosen, it may be used in place of k in the reference to the model, such as k=10 becoming 10-fold cross-validation. If k=5 the dataset will be divided into 5 equal parts and the below process will run 5 times, each time with a different holdout set.
What is the use of Cross_val_score?
The cross_val_score() function will be used to perform the evaluation, taking the dataset and cross-validation configuration and returning a list of scores calculated for each fold.
How k-fold cross-validation is implemented?
The k-fold cross validation is implemented by randomly dividing the set of observations into k groups, or folds, of approximately equal size. This procedure is repeated k times; each time, a different group of observations is treated as a validation set.
How do we choose K in k-fold cross-validation?
The algorithm of k-Fold technique:
- Pick a number of folds – k.
- Split the dataset into k equal (if possible) parts (they are called folds)
- Choose k – 1 folds which will be the training set.
- Train the model on the training set.
- Validate on the test set.
- Save the result of the validation.
- Repeat steps 3 – 6 k times.
How do I stop Overfitting?
How to Prevent Overfitting
- Cross-validation. Cross-validation is a powerful preventative measure against overfitting.
- Train with more data. It won’t work every time, but training with more data can help algorithms detect the signal better.
- Remove features.
- Early stopping.
- Regularization.
- Ensembling.
What is Cross_val_score?
2. By default cross_val_score uses the scoring provided in the given estimator, which is usually the simplest appropriate scoring method. E.g. for most classifiers this is accuracy score and for regressors this is r2 score.
What is the difference between Cross_val_score and Cross_validate?
The cross_validate function differs from cross_val_score in two ways: It allows specifying multiple metrics for evaluation. It returns a dict containing fit-times, score-times (and optionally training scores as well as fitted estimators) in addition to the test score.
What is the difference between K-fold and cross-validation?
When people refer to cross validation they generally mean k-fold cross validation. In k-fold cross validation what you do is just that you have multiple(k) train-test sets instead of 1. This basically means that in a k-fold CV you will be training your model k-times and also testing it k-times.
What is k-fold cross validation?
K-Fold Cross Validation is a common type of cross validation that is widely used in machine learning. Partition the original training data set into k equal subsets. Each subset is called a fold. Let the folds be named as f 1, f 2, …, f k . Keep the fold f i as Validation set and keep all the remaining k-1 folds in the Cross validation training set.
What is a k fold in machine learning?
K-Fold Cross Validation is a common type of cross validation that is widely used in machine learning. Partition the original training data set into k equal subsets. Each subset is called a fold. Let the folds be named as f 1, f 2, …, f k .
What is k different model in kfold?
KFOLD is a model validation technique, where it’s not using your pre-trainedmodel. Rather it just use the hyper-parameterand trained a new model with k-1 data set and test the same model on the kth set. K different models are just used for validation. It will return the K different scores(accuracy percentage)]
Does repeated k-fold cross-validation reduce statistical noise?
The expectation of repeated k-fold cross-validation is that the repeated mean would be a more reliable estimate of model performance than the result of a single k-fold cross-validation procedure. This may mean less statistical noise.